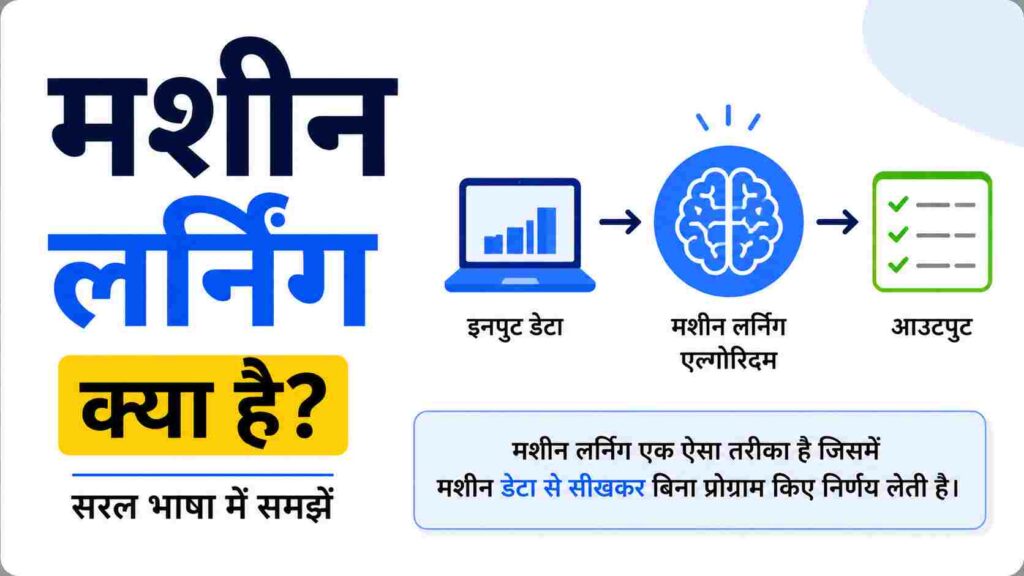
मशीन लर्निंग क्या है
मशीन लर्निंग (Machine Learning) एक ऐसी तकनीक है, जो कंप्यूटरों को बिना स्पष्ट प्रोग्रामिंग के डेटा से सीखने और निर्णय लेने की क्षमता प्रदान करती है। यह आर्टिफिशियल इंटेलिजेंस (Artificial Intelligence – AI) का एक महत्वपूर्ण हिस्सा है, जो मशीनों को मानव जैसी सोच और समझ प्रदान करता है। मशीन लर्निंग का उद्देश्य मशीनों को अनुभव से सीखने और भविष्य में बेहतर निर्णय लेने में सक्षम बनाना है। उदाहरण के लिए, ईमेल स्पैम फ़िल्टर, सिफारिश प्रणाली (Recommendation Systems), और स्वायत्त वाहन (Autonomous Vehicles) जैसी तकनीकों में मशीन लर्निंग का उपयोग किया जाता है।
मशीन लर्निंग का इतिहास (History of Machine Learning)
मशीन लर्निंग का इतिहास 1950 के दशक में शुरू हुआ। एलन ट्यूरिंग (Alan Turing) ने “क्या मशीन सोच सकती है?” (Can Machines Think?) प्रश्न उठाया, जिससे आर्टिफिशियल इंटेलिजेंस (AI) के क्षेत्र की नींव पड़ी। 1959 में, आर्थर सैमुअल (Arthur Samuel) ने मशीन लर्निंग की परिभाषा दी, जिसमें उन्होंने कहा कि मशीनों को अनुभव से सीखने की क्षमता प्रदान की जानी चाहिए। इसके बाद, 1980 के दशक में न्यूरल नेटवर्क्स (Neural Networks) और 1990 के दशक में सपोर्ट वेक्टर मशीन (Support Vector Machines – SVM) जैसी तकनीकों का विकास हुआ। 21वीं सदी में, बिग डेटा (Big Data) और क्लाउड कंप्यूटिंग (Cloud Computing) के आगमन से मशीन लर्निंग के विकास में तेजी आई। आज, मशीन लर्निंग विभिन्न उद्योगों में महत्वपूर्ण भूमिका निभा रहा है।
मशीन लर्निंग के प्रकार (Types of Machine Learning)
मशीन लर्निंग को मुख्य रूप से तीन प्रकारों में वर्गीकृत किया जाता है:
पर्यवेक्षित लर्निंग (Supervised Learning)
इस प्रकार में, मॉडल को पहले से लेबल किए गए डेटा (Labeled Data) के साथ प्रशिक्षित किया जाता है। मॉडल इनपुट और आउटपुट के बीच संबंध सीखता है और भविष्य में नए डेटा पर सही अनुमान लगाने में सक्षम होता है। उदाहरण के लिए, ईमेल स्पैम डिटेक्शन, जिसमें मॉडल को पहले से लेबल किए गए स्पैम और नॉन-स्पैम ईमेल दिखाए जाते हैं।
अप्रत्याशित लर्निंग (Unsupervised Learning)
इस प्रकार में, मॉडल को बिना लेबल किए गए डेटा (Unlabeled Data) के साथ प्रशिक्षित किया जाता है। मॉडल डेटा में छिपे पैटर्न और संरचनाओं को पहचानता है। उदाहरण के लिए, ग्राहक विभाजन (Customer Segmentation), जिसमें मॉडल ग्राहकों को उनके व्यवहार के आधार पर समूहों में विभाजित करता है।
सुदृढ लर्निंग (Reinforcement Learning)
इस प्रकार में, एजेंट (Agent) अपने पर्यावरण (Environment) के साथ इंटरएक्ट करता है और पुरस्कार (Reward) या दंड (Punishment) के आधार पर सीखता है। इसका उपयोग गेमिंग (Gaming), रोबोटिक्स (Robotics), और स्वायत्त वाहन (Autonomous Vehicles) में होता है।
मशीन लर्निंग के एल्गोरिदम (Machine Learning Algorithms)
मशीन लर्निंग में विभिन्न एल्गोरिदम का उपयोग किया जाता है, जो विभिन्न प्रकार की समस्याओं को हल करने में सक्षम होते हैं:
- लाइनियर रिग्रेशन (Linear Regression): यह एल्गोरिदम संख्यात्मक डेटा के बीच संबंध का अनुमान लगाने के लिए उपयोग किया जाता है।
- लॉजिस्टिक रिग्रेशन (Logistic Regression): यह बाइनरी वर्गीकरण समस्याओं के लिए उपयोग किया जाता है, जैसे कि ईमेल स्पैम डिटेक्शन।
- निर्णय वृक्ष (Decision Tree): यह डेटा को विभाजित करने के लिए एक पेड़ संरचना का उपयोग करता है, जिससे निर्णय लेने की प्रक्रिया सरल होती है।
- रैंडम फॉरेस्ट (Random Forest): यह कई निर्णय वृक्षों का संयोजन है, जो अधिक सटीक परिणाम प्रदान करता है।
- न्यूरल नेटवर्क्स (Neural Networks): यह मानव मस्तिष्क की संरचना से प्रेरित है और जटिल पैटर्न पहचानने में सक्षम है।
मशीन लर्निंग की प्रक्रिया (Machine Learning Process)
मशीन लर्निंग की प्रक्रिया में निम्नलिखित चरण शामिल होते हैं:
- डेटा संग्रहण (Data Collection): उद्देश्य से संबंधित और पर्याप्त डेटा इकट्ठा करना।
- डेटा पूर्व-प्रसंस्करण (Data Preprocessing): डेटा की सफाई, सामान्यीकरण, और फीचर इंजीनियरिंग।
- मॉडल चयन (Model Selection): डेटा और समस्या के अनुसार उपयुक्त एल्गोरिदम चुनना।
- मॉडल प्रशिक्षण (Model Training): मॉडल को डेटा पर प्रशिक्षित करना।
- मॉडल मूल्यांकन (Model Evaluation): मॉडल की सटीकता, संवेदनशीलता, और प्रदर्शन का मूल्यांकन।
- मॉडल परिनियोजन (Model Deployment): वास्तविक दुनिया में मॉडल को लागू करना।
मशीन लर्निंग के अनुप्रयोग (Applications of Machine Learning)
मशीन लर्निंग का उपयोग विभिन्न क्षेत्रों में किया जाता है:
- स्वास्थ्य देखभाल (Healthcare): रोगों की पहचान, उपचार सिफारिशें, और चिकित्सा छवियों का विश्लेषण।
- वित्त (Finance): धोखाधड़ी का पता लगाना, क्रेडिट स्कोरिंग, और निवेश रणनीतियाँ।
- विपणन (Marketing): ग्राहक विभाजन, सिफारिश प्रणाली, और विज्ञापन लक्ष्यीकरण।
- परिवहन (Transportation): स्वायत्त वाहन, यातायात प्रवाह विश्लेषण, और मार्ग अनुकूलन।
- मनोरंजन (Entertainment): संगीत और फिल्म सिफारिशें, सामग्री अनुशंसा, और उपयोगकर्ता अनुभव अनुकूलन।
मशीन लर्निंग के लाभ (Benefits of Machine Learning)
मशीन लर्निंग के कुछ प्रमुख लाभ हैं:
- स्वचालन (Automation): मैन्युअल कार्यों को स्वचालित करके समय और संसाधनों की बचत।
- सटीकता (Accuracy): बड़े डेटा सेटों से पैटर्न पहचानने में उच्च सटीकता।
- अनुकूलन (Optimization): निर्णय लेने की प्रक्रिया को बेहतर बनाना।
- व्यक्तिगत अनुभव (Personalized Experience): उपयोगकर्ताओं के लिए व्यक्तिगत सिफारिशें और अनुभव प्रदान करना।
मशीन लर्निंग की चुनौतियाँ (Challenges in Machine Learning)
मशीन लर्निंग के सामने कुछ प्रमुख चुनौतियाँ हैं:
- डेटा की गुणवत्ता (Data Quality): खराब गुणवत्ता वाला डेटा मॉडल की सटीकता को प्रभावित कर सकता है।
- अत्यधिक डेटा (Big Data): बड़े डेटा सेटों को संसाधित करना और विश्लेषण करना चुनौतीपूर्ण हो सकता है।
- मॉडल की व्याख्यात्मकता (Model Interpretability): जटिल मॉडल्स को समझना और व्याख्यायित करना कठिन हो सकता है।
- नैतिक मुद्दे (Ethical Issues): डेटा गोपनीयता, पूर्वाग्रह, और निर्णय लेने में पारदर्शिता के मुद्दे।
मशीन लर्निंग के उपकरण और पुस्तकालय (Tools and Libraries for Machine Learning)
मशीन लर्निंग के विकास के लिए विभिन्न उपकरण और पुस्तकालय उपलब्ध हैं:
- पायथन (Python): एक प्रमुख प्रोग्रामिंग भाषा, जिसमें मशीन लर्निंग के लिए कई पुस्तकालय हैं।
- टेंसरफ़्लो (TensorFlow): गूगल द्वारा विकसित एक ओपन-सोर्स पुस्तकालय, जो गहन शिक्षण (Deep Learning) के लिए उपयोगी है।
- पांडा (Pandas): डेटा विश्लेषण और संरचना के लिए एक पुस्तकालय।
- स्काईट-लर्न (Scikit-learn): सामान्य मशीन लर्निंग एल्गोरिदम के लिए एक पुस्तकालय।
- केरस (Keras): गहन शिक्षण के लिए एक उच्च-स्तरीय पुस्तकालय।
मशीन लर्निंग और पारंपरिक प्रोग्रामिंग में अंतर (Difference Between Machine Learning and Traditional Programming)
| मशीन लर्निंग (Machine Learning) | पारंपरिक प्रोग्रामिंग (Traditional Programming) |
|---|---|
| डेटा से सीखता है | स्पष्ट निर्देशों के आधार पर कार्य करता है |
| भविष्यवाणियाँ करता है | पूर्वनिर्धारित नियमों का पालन करता है |
| अनुभव से सुधारता है | कोड में परिवर्तन के माध्यम से सुधारता है |
मशीन लर्निंग का भविष्य (Future of Machine Learning)
मशीन लर्निंग का भविष्य उज्जवल है, और इसके विकास की दिशा निम्नलिखित क्षेत्रों में हो सकती है:
- स्वायत्त प्रणालियाँ (Autonomous Systems): स्वायत्त वाहन, ड्रोन, और रोबोटिक्स में मशीन लर्निंग का उपयोग बढ़ेगा।
- स्वास्थ्य देखभाल में सुधार (Advancements in Healthcare): रोगों की पूर्वानुमान, व्यक्तिगत उपचार, और चिकित्सा अनुसंधान में मशीन लर्निंग की भूमिका बढ़ेगी।
- वित्तीय सेवाओं में सुधार (Enhancements in Financial Services): धोखाधड़ी का पता लगाना, जोखिम मूल्यांकन, और निवेश रणनीतियों में मशीन लर्निंग का उपयोग बढ़ेगा।
- शिक्षा में सुधार (Improvements in Education): व्यक्तिगत शिक्षा, छात्र प्रदर्शन विश्लेषण, और शिक्षण विधियों में मशीन लर्निंग की भूमिका बढ़ेगी।
निष्कर्ष (Conclusion)
मशीन लर्निंग एक शक्तिशाली तकनीक है, जो विभिन्न क्षेत्रों में क्रांति ला रही है। इसके माध्यम से, हम डेटा से महत्वपूर्ण जानकारी प्राप्त कर सकते हैं और बेहतर निर्णय ले सकते हैं। हालांकि, इसके उपयोग में नैतिक और सामाजिक जिम्मेदारियाँ भी शामिल हैं, जिन्हें ध्यान में रखते हुए इसका विकास और उपयोग किया जाना चाहिए।

नमस्कार, मैं आशीष दुबे हूँ। मुझे टेक्नोलॉजी को समझना और उसे आसान हिंदी में लोगों तक पहुँचाना पसंद है। Tech in Hindi के माध्यम से मैं इंटरनेट, मोबाइल, कंप्यूटर और नई तकनीकों से जुड़ी उपयोगी जानकारी साझा करता हूँ, ताकि हर हिंदी पाठक डिजिटल दुनिया से जुड़े रह सके।